



予測精度を上げるのは組織作りから
通販最大手の(株)千趣会は、1995年4月からデータマイニングに取り組んでいる。同社の中心的事業である通販では、顧客の顔を直接見ることはできない。だからこそ“顧客を見る”技量が要求される。この観点から同社では、1995年にデータウェアハウスを構築、データベース・マーケティングに乗り出した。現在では、カタログの配付先の選定から、業務の効率化、経営の効率化まで、情報をフル活用した企業戦略を展開している。
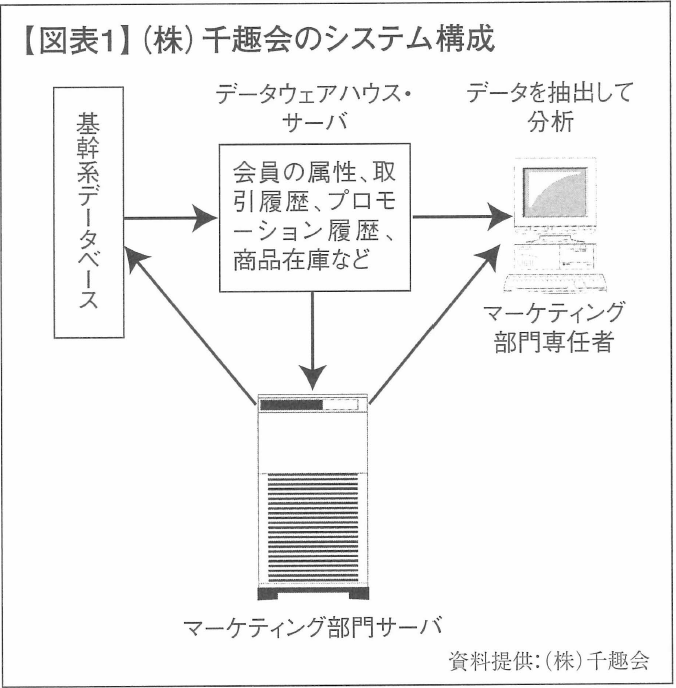
同社が当初構築したのは、DM・カタログのプロモーション履歴、顧客属性、過去3年間の取引履歴、商品在庫などの情報を蓄積した、240ギガバイトの容量をもつデータウェアハウス。この折には、“エンド・ユーザー・コンピューティング”の考えから、ユーザーの立場に立って、商品開発やマーチャンダイジングの現場のスタッフがデータマイニングを行うことを指向した。
しかし、実際にデータマイニングをはじめてみたところ、データマイニングには、スペシャリストが必要だとの結論に達した。データマイニングには統計、マーケティング、SQL(構造化照会言語)の知識が不可欠であり、特に数字を扱う統計分析においては、高度な技術が要求される。特に入力における小さな変化が出力に大きな変化を与える非線形関数の場合、準備する使用データ(説明変数)や答えを得るための手続き(アルゴリズム)をどう選ぶかが重要で、これは経験とセンスによるところが大きいからである。また、はじめは定型的な分析メニューを組み込み、それに基づいて分析を行っていたものの、この方法では現状の把握、現状の問題解決にしか役立たないということがわかってきた。
データマイニングの神髄は“予測”である。つまり、現状分析にとどまらず、この予測の確率を高めていくことが最大のポイントとなる。たとえば、顧客との関係を強化するCRMでも、営業の効率化を図るSFAでも、あるいはスピーディーな意志決定をサポートする仕組みでも、“予測”ができれば、当然の結果としてスピードが上がる。それだけ効率が良くなるわけだ。効率を求めて仕組みを作るのなら、この予測の精度が低ければ、意味がないのである。
そこで同社では、この予測の精度の向上にこだわって、そのためにはどのようにスタッフを配置するべきか、どういったシステムやツールを選択すべきかを、十分に検討した。そして1998年にデータウェアハウスを刷新。より多くの顧客情報を保管できるように、1.7テラバイトにまで容量をアップした。同時に顧客データの保管期間を6年に延長。また、従来プログラムに組み込んでいた定型メニューをはずし、収集した情報をもとに、より専門的な分析をし、その“予測”を踏まえて、データが活用ができるさまざまな工夫を加えた。
現在、データマイニングに携わるスタッフは17名。このうち4名はSQL作成の専任者である。SQL作成には、データベースに関する深い知識が必要であることと、検索処理に時間を要することから、最大限の効率を上げるために、SQL担当者と分析の担当者を分けた。分析担当者のうち6名は、専門媒体、衣料開発、雑貨開発のユーザー部門に配属され、現場ごとに分析業務に当たっている。データウェアハウスは、処理能力のすばやさから日本NCRのWorld Mark4700を導入。データマイニングのためのツールとしては、SPSSのClementineのほか、SASの製品などを併用している。
通販業務を最適化
通販で売り上げを確保するためには、購入見込み度の高い顧客にカタログを送り届け、在庫を圧縮しながら、かつ欠品を防止し、確実に販売していかなくてはならない。カタログの配布と品揃えの“最適化”は、通販企業にとっての永遠の課題である。同社では、データマイニングによってこの課題の解決を図っているのだ。
マーケティングにおいては、たとえば「誰にどのカタログを配布するか」の判断に利用。同社は、基幹カタログ『ベルメゾン家族』のほか、約20種類の各種スペシャル・カタログを発行しているが、データマイニングによってこれらのカタログごとに、顧客にカタログを送った場合、どのくらい購入するかという予測金額を推定(これを「期待金額」と呼んでいる)。一方、カタログの作成や送付、商品の原価、配送料等のデータから、カタログや商品を送った場合にいくらかかるかという「標準原価」を独自に設定しており、これに「期待金額」を照らし合わせ、「期待金額」が「標準原価」を上回ると予測される顧客にのみカタログを配付している。
このほか、データウェアハウスに蓄積された顧客属性、取引履歴、メーカー評価、媒体のマーケット分析、プロモーション分析などの情報を駆使して、カタログの効果的な組み合わせなどを予測し、成果を上げた。ちなみに1998年度には、カタログの発行部数を前年と比べて750万部削減した。
カタログの配布先の決定と同時に、デーマイニングにより受注時期も予測。いつ、どのくらい商品を仕入れればいいか、あるいはどの時期に何人のテレコミュニケータを配置すればいいのかといった詳細な販売計画を立てている。この販売計画は、カタログの発行後も、実際の受注情報を加えながら、随時変更されていく。
同社 マーケティング部 部長 大東敏明氏は、こうしたデータベース・マーケティングがこれまでのマス・マーケティングと異なるのは、その要素である4P(Product、Price、Place、Promotion)に、もうひとつのP、つまり“Personal”な情報が加わっている点だと言う。これまで売り上げは「価格×個数」で分析されたきた。しかし、データベース・マーケティングでは「顧客数×顧客単価」で分析される。つまり、売り上げを上げるための最も重要なファクターとして顧客数が浮かび上がり、顧客維持、新規顧客獲得に向け、パーソナルな情報が必要不可欠なものとして再認識されるに至った。
同社では、データマイニングを開始して以来、RFM分析を行っていない。データマイニングの手法を用い、最終購入日、購入頻度、購入金額といった従来の情報に、たとえばその顧客がどのような商品ジャンルを好むかというパーソナルな情報を加えることで、RFM分析とは比較にならないほどに精度の高い分析結果が得られるようになったからである。
こうしたパーソナルな情報収集について、前述の大東氏は「顧客からは性別、年齢、既婚か未婚か、子供の有無についての情報が得られれば十分」と語る。同社では、顧客がはじめて注文した時にこれらの情報を注文書や電話で収集しているが、趣味、ライフスタイルといった不確定な情報は収集していない。これらの要素は、その顧客が何を買ったか、使った金額はいくらか、そして、同社や個別のカタログに対するロイヤルティがどの程度かを数値化することで推測できるからである。
またデータマイニングは、マーケティングのみにとどまらず、フルフィルメントから仕入先に至るまで、ビジネスを構築するすべての企業活動を最適化するツールとなっている。データ化することで、いつ、どのようなカタログを、どういった顧客に配布し、結果がどうなったのかという“業務の流れ”、商品がいつ入荷し、誰に販売し、それがどうなったのかという“商品の流れ”、そして、マーチャンダイジングにいくら投資し、仕入れの費用をいつ払ったのかなどの“資金の流れ”を把握・分析することが可能になった。データマイニングは事業変革、課題解決の施策を発見・検証する一連の活動をサポートしているのである。
その効果は、同社の実績に如実に反映されている。1999年3月期は、売上高こそ前年同期比11%の減少となったものの、経常利益は71%と大幅に増加した。同社は、今後も、データマイニングの予測精度を追求することで、売り上げの拡大、そして顧客とのより親密な関係を構築しようとしている。


